2024. 11. 5. 23:59ㆍ카테고리 없음
0. 사전에 진행했던 내용들
원래 DAB 경진대회의 주제는 '노년층 및 디지털약자의 디지털 격자 해소를 위한 AI 객체탐지, 음성 인식 서비스' 로 진행했었다. 그래서 해당 주제를 진행하기 위하여 다음과 같은 활동 계획서도 작성하고, 사전 연구 코드들도 뒤졌었다.
따라서 이를 직관적으로 보여줄수 있는 버거킹의 UI 를 크게 크게만들고, 60대 이상의 사용자들에게 설문조사도 받는등의 진행을 하였다.


1. 문제를 잘못된 방향으로 해석한것은 아닌지?
진행한 내용을 기반으로 9월중 중간 발표가 있었다. 전반적으로 준비한 내용을 잘 전달 하였으나
교수님들 께서는 제안 주제에 대한 근본적인 문제점 지적이 있었다.
'키오스크 사용이 어려운것이라면 그냥 식당이나, 매장에서 상주하고 있는 사람이 해주는게 시스템 도입 자체까지 하면서 진행하는 것보다 더 명확한 방법이 아니겠는지?'
이질문에 Digital Transformation 이야기를 하면서 적당히 도입의 필요성에 대한 이야기를 했으나, 최근 방문했던 식당에서 다음과 같은 키오스크의 문구를 보고 주제에 대한 맘을 접었다.

2. 그래서 새롭게 가져온 주제는?
"Get-cha SPAM- ✰ Without training"
LLM Zero-shot Anomaly Detection with Auto-Text Pattern Recognition
다음과 같은 주제를 하게 된 배경은
1) 시간적인 제약(일주일안에 갈아 엎어야함)
2) 당근테크밋업에서 들었던 내용 기반으로 적용해보고 싶은 마음에서였다.
3. 당근 테크 밋업의 Reference?

발표의 내용은 다음과 같았습니다.
당근마켓에서 전문판매업자들이 플랫폼을 악용하는 문제를 해결하기 위해 LLM과 임베딩 유사도를 활용한 패턴 탐지 솔루션을 제안하였고, 이를 통해 변화하는 패턴을 가진 악성 업자들의 게시글을 효율적으로 탐지하고 관리하는 방법론을 구축
[문제의식]
전문판매업자들은 반복적으로 계정을 생성하여 다량의 게시글과 채팅을 도배하는 방식으로 영업을 합니다. 이로 인해 정상적인 사용자의 거래 경험이 훼손되고, 악성 업자들의 패턴이 계속해서 변화하면서 기존의 수동 관리 방식은 효과를 발휘하기 어렵다는 문제점이 있음
[기존 해결방안과 한계]
기존에는 보안 정책 강화와 Supervised Learning을 통한 컨텐츠 패턴 탐지를 사용했습니다. 그러나 다음과 같은 한계가 있었습니다:
- 새로운 패턴이 발견되기 전까지 데이터를 반영하기 어려움.
- 패턴 변화에 맞추어 빠르게 학습하기 위해 많은 양의 데이터가 필요함.
- 다양한 유형의 업자 패턴을 통합해 처리함으로써 개별 특성을 반영하지 못함.
[새로운 해결방안]
이에 당근에서는 LLM Zero-Shot Classification과 유사 콘텐츠 탐지를 통해 위 한계를 해결하고자 했습니다.
- 유사 콘텐츠 탐지: 컨텐츠의 임베딩 유사도를 사용하여 유사한 패턴을 가진 게시글을 실시간으로 탐지합니다. 이로써 LLM 모델이 빠르게 변화하는 패턴을 자동으로 분류할 수 있습니다.
- Zero-Shot with Auto-Generated Prompt: 이전에 탐지된 업자 패턴을 통해 특성을 추출하고, 새로운 게시글을 Prompt 기반으로 탐지하는 방식을 적용했습니다.
[성과]
- 정확도: 유사 콘텐츠 로직이 기존 방식보다 높은 정밀도(Precision 98.7%)와 회수율(Recall)을 달성하였습니다.
- 비용 절감: 대량의 라벨링 작업 없이도 효율적인 탐지가 가능해졌고, LLM 호출 비용 절감 효과도 있었습니다.
[결론]
Supervised Learning의 한계를 보완한 Zero-Shot 분류와 유사 콘텐츠 탐지 방식이 플랫폼에서 실시간으로 악성 업자를 효과적으로 탐지할 수 있었다.
4. 그렇다면 이 reference를 어떻게 사용할 건데?

이러한 레퍼런스를 이용하여 실제 대모를 만들기 위한 사고의 흐름은 다음과 같았다.
1. 일상생활의 classification 문제를 풀어보자
2. 쉽게 구할 수 있는 데이터 셋은 무엇이 있을까?
3. 그럼 그 데이터셋으로 classification 문제를 풀었을때 사회적 파급력은 어떻게 되는가?
4. (구현 부분) 실제로 잘 걸러내는지? 잘 구현이 되는지?
5. accuracy 는 높은지?
6. DEMO 로 구현해서 유저에게 제공했을때 재밌어할지?
이 회로속에서 Y 로 정리되는 주제를 쉽게 찾을 수가 없었었고 결과적으로는
클래식한 문제라고 생각할수도 있는 '스팸 메세지 걸러내기' 라는 문제였다.
(사실은 리뷰데이터를 가지고 하고 싶었지만) 리뷰데이터의 긍부정을 가지고 사용하고 싶었는데, 이는 DEMO 에서 유저가 공감을 가지고 재밌어하기는 쉽지 않겠다는 판단으로 스팸 메세지로 결정하였다.
왜냐하면 우리는 실시간으로 문자메세지를 받아서
(Imessage를 사용했다) 연동해서 실시간 show 를 보여주고 싶은 마음 때문이었다.
5. Architecture 는?

1) Data Collection
스팸 탐지에 필요한 텍스트 데이터를 수집합니다.
이때에는 일반적인 classification 문제와 다르게 걸러내야하는 소량의 '스팸' 메세지만 존재하면 됩니다.
(단순히 pattern 을 뽑아내는 목적이기 때문에)
2) Auto-Text Pattern Recognition (by prompting)
LLM 을 활용하여 수집된 데이터에서 텍스트 패턴을 자동으로 인식시킵니다. 이 과정에서 LLM 은 특이한 문자 조합, 특정한 단어 패턴, 변형된 언어등을 인식하며 스팸에 나타내는 반복적인 특성을 파악합니다.
이를 통해 사전에 학습되지 않은 새로운 유형의 스팸 패턴을 포착할 수 있습니다.
3) SPAM classification (by prompting)
이전 단계에서 인식된 패턴을 바탕으로 입력된 메시지가 스팸인지 아닌지를 판단합니다. 이때 Zero-shot 기능을 활용하여 사전 학습 없이도 다양한 스팸 패턴을 이해하고 분류합니다
이 방식이 Zero-shot 방식인 이유는 사전 학습 데이터 없이도 새로운 유형의 스팸을 탐지할 수 있는 능력을 가지고 있기 때문입니다. 일반적으로 스팸 탐지와 같은 작업에서는 모델이 특정 유형의 스팸 메시지에 대한 예제 데이터를 미리 학습해야만 정확하게 분류할 수 있습니다. 그러나 Zero-shot 방식에서는 이러한 사전 학습이 필요하지 않습니다.
이미 LLM(GPT)에서는 방대한 일반 텍스트 데이터로 학습되어 다양한 문맥과 패턴을 이해할 수 있는 능력을 갖추고 있습니다. 이를 통해 특정 도메인이나 유형의 데이터를 별도로 학습하지 않고도 새로운 형태의 스팸을 인식할 수 있습니다. 예를 들어, 모델은 "긴급"이나 "할인" 같은 특정 단어가 반복적으로 사용되는 문맥을 보고 이를 의심스러운 패턴으로 판단할 수 있습니다.
또한 스팸 메시지의 패턴은 빠르게 변화하기 때문에 기존의 Supervised Learning 방식으로는 새롭게 나타나는 패턴을 신속히 대응하기 어렵습니다. Zero-shot 방식은 대규모 언어 모델의 일반적인 언어 이해를 활용하여 새로운 패턴을 탐지할 수 있으므로 스팸 패턴이 변하더라도 즉각적으로 대응할 수 있다는 장점이 있습니다.
따라서, 이 시스템은 Zero-shot 방식을 사용하여 사전 학습 데이터 없이도 변화하는 스팸 패턴을 인식하고 대응할 수 있는 유연성과 효율성을 제공할 수 있습니다.
4) prediction
앞의 두 모델을 거처 Prediction 을 진행합니다. 이 prediction 은 Danger, Warning, Safe 로 3가지로 나누었으며
danger랑 warning 으로 나타난다면 CoT를 사용하여 왜 스팸메세지로 판단하였는지 이유를 함께 출력 하게 하였습니다.

6. 살 붙여서 하나의 프로덕트처럼 만들기
[1. 프로젝트 배경과 개요]
스팸 메시지는 현대 사회에서 커다란 문제로 자리 잡았으며, 피해 사례도 매년 증가하고 있습니다. 최근 몇 년 동안 특히 스미싱이나 피싱 메시지의 빈도가 급증하면서, 단순 광고뿐만 아니라 금융 사기와 같은 형태로 진화하고 있습니다. 이러한 변화는 사용자와 기업에 경제적 손실과 불편을 초래하며, 스팸 탐지 시스템의 고도화가 필수적으로 요구되고 있습니다.
이번 프로젝트의 목표는, 대규모 언어 모델(gpt)을 활용해 기존 스팸 탐지 시스템의 문제점을 보완하고 더욱 정확하고 빠르게 탐지할 수 있는 AI 기반 스팸 탐지 시스템을 개발하는 것이었습니다. SKT, KT, LG U+ 등 통신사를 대상으로 하여, 일반적인 키워드 필터링 방식을 우회하는 특수 문자와 변형된 단어를 탐지하는 AI 시스템을 설계하고자 했습니다.
[ 2. 문제 정의 및 기존 시스템의 한계]
스팸 메시지의 급증과 탐지 시스템의 한계: 경찰청 자료에 따르면, 스팸 메시지 신고 건수는 최근 몇 년 동안 급격히 증가하고 있습니다. 특히, 2023년 신고 건수는 전년 대비 약 676% 증가했으나, 기존 스팸 탐지 시스템은 이와 같은 변화에 빠르게 대응하지 못하고 탐지율이 약 90%나 감소하는 상황이었습니다. 스팸 메시지가 날로 진화하면서 기존 시스템이 스팸을 정확히 분류하는 데 어려움을 겪고 있으며, 이는 데이터 수집과 관리 비용 문제까지 야기하고 있습니다
기존 머신러닝 방법의 한계: 기존 스팸 탐지 방법은 주로 머신러닝과 규칙 기반 필터링 방식을 결합하여 구현되었습니다. 머신러닝 분류기는 수집된 데이터를 기반으로 학습하여 스팸과 정상 메시지를 분류하는데, 이는 특수 문자나 변형된 단어가 포함된 메시지를 탐지하는 데에 어려움이 있습니다. 예를 들어, '카지노'와 같은 단어를 스팸 메시지로 인식하도록 설정해도, 특수 문자를 포함한 'ⓒⓐ$1Nⓞ'와 같은 변형된 형태를 탐지하는 데 한계가 발생합니다.
새로운 스팸 유형에 대한 대응 문제: 새로운 유형의 스팸 메시지가 등장할 때마다 이를 탐지하기 위해 모델을 재학습해야 합니다. 이는 데이터 라벨링의 노동집약적 작업과 데이터 불균형 문제를 야기하며, 시간이 지남에 따라 시스템 효율성이 저하됩니다. 이러한 상황에서 anomaly detection을 위한 데이터 수집이 매우 어렵고, 정상과 비정상 데이터를 구분하는 것에 대한 비용 부담도 상당합니다.
[3, 제안 솔루션: LLM 기반 스팸 탐지 시스템 ]
기존 방법의 한계를 극복하기 위해, 저희는 대규모 언어 모델을 활용하여 Zero-shot Anomaly Detection과 Auto-Text Pattern Recognition을 결합한 새로운 접근법을 제안했습니다. 이는 새로운 유형의 스팸 메시지가 발생하더라도 추가 학습 없이 탐지가 가능하도록 설계되었습니다.
- LLM 기반의 Zero-shot Anomaly Detection: 사전 학습이 필요하지 않으며, 새로운 스팸 패턴이 발생했을 때에도 모델이 빠르게 반응할 수 있습니다. 대규모 언어 모델은 특수 문자나 변형된 단어를 인식할 수 있는 능력을 가지고 있으며, 이를 통해 새로운 형태의 스팸 메시지에 대한 대응 속도를 높일 수 있습니다.
- Auto-Text Pattern Recognition: 대규모 언어 모델을 활용하여 메시지의 패턴을 분석하고, 변형된 텍스트 내에서도 의도를 파악할 수 있는 기술을 도입했습니다. 이를 통해 스팸 메시지 분류 과정에서 특수문자나 변형된 단어를 포함한 메시지를 효과적으로 탐지할 수 있으며, 새로운 스팸 유형이 발생해도 라벨링 및 추가 데이터 수집의 필요성이 줄어들었습니다.
- 데이터 수집 및 관리의 효율성: 제안된 방법은 소량의 스팸 데이터만 필요로 하며, 기존의 노동집약적 라벨링 작업을 줄일 수 있습니다. 또한, anomaly detection에서 발생하는 데이터 불균형 문제를 해결하여 데이터 관리와 적재에 필요한 비용을 절감할 수 있습니다
[4. 검증 및 성능 평가]
- 정량 평가: 다양한 스팸 탐지 모델의 성능을 비교한 결과, LLM 기반 시스템이 높은 정밀도와 재현율을 기록하며, 기존 머신러닝 및 딥러닝 모델을 능가했습니다. 특히 F1 Score에서 0.99의 높은 점수를 기록하며, 스팸과 정상 메시지를 구분하는 데 매우 효과적임을 확인했습니다.

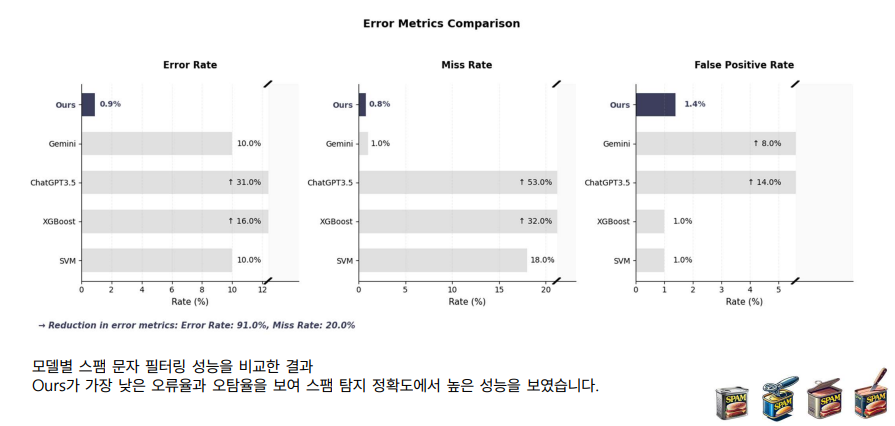
Error Rate, Miss Rate, False Positive Rate 세 가지 지표 모두에서 가장 낮은 수치를 기록하여 스팸 탐지 성능이 다른 모델들보다 우수함을 입증하고 있습니다. 특히, 낮은 Miss Rate 덕분에 스팸 메시지를 놓치는 경우가 거의 없으며, False Positive Rate 역시 낮아 정상 메시지를 스팸으로 오탐할 가능성이 적습니다.
- Error Rate (오류율): 스팸 메시지를 올바르게 탐지하지 못한 전체 오류 비율입니다. 저희 모델은 0.9%로 가장 낮은 오류율을 기록하였으며, 다른 모델들(Gemini, ChatGPT3.5, XGBoost, SVM)은 10% 이상의 오류율을 보였습니다. 이는 "Ours" 모델이 전반적으로 높은 정확도로 스팸 메시지를 필터링했음을 의미합니다.
- Miss Rate (누락률): 스팸 메시지를 탐지하지 못하고 놓친 비율을 의미합니다. 저희 모델의 Miss Rate는 0.8%로, 이 또한 가장 낮은 수치를 보입니다. Gemini와 ChatGPT3.5 모델의 Miss Rate는 각각 1%와 18%로 비교적 높은 수치를 보이며, 특히 XGBoost와 SVM 모델은 각각 32%와 53%로 더 많은 스팸 메시지를 놓쳤음을 나타냅니다.
- False Positive Rate (오탐율): 정상 메시지를 스팸으로 잘못 분류한 비율입니다. 저희 모델의 False Positive Rate는 1.4%로, 다른 모델들보다 낮은 수치를 기록했습니다. Gemini와 ChatGPT3.5 모델은 각각 8%와 14%의 높은 오탐율을 보였으며, XGBoost와 SVM 모델은 1%로 비교적 낮은 오탐율을 보였지만, 전체적인 오류율과 누락률에서는 "Ours" 모델에 미치지 못합니다.
- 정성 평가: 스팸 탐지 과정에서 발생한 오분류 메시지를 통해 분류 기준을 점검하고 보완할 수 있었습니다. 이 과정에서 패턴 분석의 정확성을 높이기 위해 Chain of Thought(CoT) 방식을 적용하여 모델이 왜 스팸 메시지로 판단했는지 그 이유를 출력하도록 하여, 보다 직관적이고 신뢰할 수 있는 탐지 결과를 제공했습니다
[5.활용 가능성 및 향후 적용 분야]
대규모 언어 모델을 활용한 제안 시스템은 스팸 탐지 외에도 여러 산업에서 응용 가능성이 큽니다. 예를 들어, 변형된 문자를 포함한 사용자 리뷰를 분석하고 의도를 이해하여, 소셜 미디어 성과 분석이나 온라인 마케팅 전략 개선에 활용할 수 있습니다. 또한, OCR(Optical Character Recognition) 기술과 결합하여 이미지 내 텍스트를 번역할 때에도 변형된 문자나 은어를 정확하게 인식하고 해석할 수 있습니다.
특히, 한국어뿐만 아니라 다양한 언어에서도 특수문자나 변형된 표현을 포함한 텍스트를 정확하게 인식할 수 있다는 점에서, 글로벌 비즈니스 확장에도 도움이 될 것으로 기대됩니다. 예를 들어 숙박업 후기 요약 서비스에서 고객의 감정 분석을 통해 맞춤형 서비스를 제공하거나, 고객 후기를 요약하여 정보 불균형 문제를 해결하는 데에도 유용하게 적용될 수 있습니다.
7. Demo
한번 사용해보기 : https://kubs-spam-opener.streamlit.app/
Spam Opener
This app was built in Streamlit! Check it out and visit https://streamlit.io for more awesome community apps. 🎈
kubs-spam-opener.streamlit.app

시현 영상
https://youtu.be/n-uh0OrRmJ8
8. How-To
일반적으로 HOW-TO 까지는 관심이 없지 않을까 싶어서 맨 뒤로 뻈다.
프로젝트를 진행하면서 어려웠던 부분에 대하여 정리 해보자.
[1] 데이터셋 구하기
: 진짜 이게 제일 어려웠다. 스팸 문자의 경우 유료 데이터 셋으로 요기에 있었지만,
https://www.bigdata-policing.kr/product/view?product_id=PRDT_105
스마트치안 빅데이터 플랫폼
www.bigdata-policing.kr
30만원씩이나하는데, 비용에 대한 부담은 어찌할수가 없어서 대체 방법으로
여기에 있는 데이터 셋 일부 사용과
https://www.kaggle.com/competitions/2021-ai-w12-p1/dataKB 금융 그룹에서 지난 2019년에 진행했던 해커톤의 데이터를 사용하고 싶었으나
https://dacon.io/competitions/open/235401/overview/description 데이터셋은 사용후 회수 되기 때문에 상위권팀들의 github repo 에 잔재되어있는 데이터셋을 이용하여 걸러내었다.
[2] 데이터셋 증강하기
스팸 문자메세지는 쉽게 구했으나(구현을 위한)
평가를 위한 일반 메세제의 경우는 구하기 쉽지 않았다. 추측컨데 일반 사용자의 개인정보나 상황이 너무 많이 들어가 있어서가 아닐까...
결국 따라서 기존에 내가 가지고 있는 일반 문자메시와 gpt에게 생성하도록 만들어서 Data Augentation 을 진행하였다. 하기 논문을 참고해서 프롬프트를 만들어서 증강을 진행하였다. https://arxiv.org/pdf/1901.11196

증강 방법 1) 텍스트 페러프레이징 - "content": "주어진 한국어 텍스트를 다양한 방식으로 패러프레이징하고 대답의형태로 표현해주세요."
증강 방법 2) "문맥을 고려한 텍스트 증강 - "content": "주어진 텍스트의 문맥을 유지하면서, 일부 단어나 구절을 유의어로 대체하여 자연스러운 새로운 문장을 만들어주세요."
증강 방법 3) 역번역 - "content": "영어로 번역했다가 다시 한국어로 바꿔주세요 ."
증강 방법 4) Random Insertion - "content": "불용어가 아닌 임의의 단어를 무작위로 삽입해주세요.
와 같은 방법을 사용하였다.
[3] 실시간 문자 메세지 연동하기
보는 사람 입장에서 ' 우와 나도 써보고 싶다' 같은 느낌을 주고 싶었기 때문에 실시간 문자가 연동이 되게 하는데 쓸데 없이(?) 시간을 많이 썻다. 한국은 별도의 사업자 번호를 가지고 있는게 아니라면 웹상에서 메일을 수신하게 끔 하는데 다소 어려움이 있었다. 따라서 카카오톡 개발자 도구 이용해서 카톡으로 받아볼까 했지만, 이또한 사업자등록증을 내고 신청하고 수락 받는데 까지 꽤 시간이 걸리기 때문에 다른 방법들을 계속 찾았다.
대체안 : 같이 팀 프로젝트를 하는 친구가 mac 을 쓰는데, 이 mac 의 경우는 i message 에 실시간으로 연동된다. 따라서 해당 message 를 DB에 적재해서 최근 1개 '-1' 의 메세지만 자동으로 가지고 와서 input 값에 넣도록 하였다.
따라서 우리의 레포에는 db가 존재한다.
cf. 나중에는 일반 안드로이드 유저도 사용해보게 끔 하기 위해 텍스트를 쓸수 있도록 하는 부분도 추가했다.
현재 올라가 있는 streamlit 에서는 '새로운 메세지 확인하기' 버튼을 누르면 앞에 사용자 직접 입력했거나, mac 환경에서 실시간으로 써서 insert 된 부분이 나오게 된다.
# 세션 상태 초기화
if 'messages' not in st.session_state:
st.session_state.messages = []
# AI 분석 결과를 저장할 리스트를 초기화
if 'results' not in st.session_state:
st.session_state.results = []
# 새로운 메시지가 추가되었는지를 추적하는 상태 변수 초기화
if 'new_message_added' not in st.session_state:
st.session_state.new_message_added = False
if st.button("새로운 메시지 확인하기"):
external_data = get_external_data() # 최신 메시지 가져오기
if external_data:
# external_data는 리스트 안에 튜플 형태로 되어 있으므로, 첫 번째 튜플의 첫 번째 요소를 가져옵니다.
message_text = external_data[0][0] # 메시지 텍스트 추출
st.session_state.messages.append({"role": "user", "content": message_text, "timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")})
st.session_state.new_message_added = True # 메시지 추가됨을 추적
[4] 프롬프트 잘짜기
이 프로젝트를 진행하면서 가장 많은 고민을 한 부분은 우리가 만든 이게 얼마나 크게 사회에 도움이 될지에 대한 부분에 좀더 신경을 썼다. 사실 구현 자체는 그렇게 어려운 부분은 아니었기 떄문에.. (모두 프롬프트로 해결했다.)
우리 모델에서 두가지 모듈이 있었다.
모듈 1 ) 문자 메세지를 받아서 어떤 pattern 을 가지고 있는지 특성을 뽑아내는 모듈
당신은 스팸 문자메시지의 패턴 인식을 발견하는 전문가입니다. 100개의 스팸 문자메시지가 입력되었을 때, 이 문자들에서 자주 발생하는 패턴을 찾아내는 것이 당신의 목표입니다.
주의해야할 점은 스팸메시지에서 일반적으로 나타나는 패턴이 아닌, 제가 입력하는 데이터에서만 나타나는 패턴을 인식해야 합니다.
입력되는 데이터는 '<문자시작> ' + 문자메시지 + ' <문자끝>'을 기준으로 구분될 수 있습니다.
패턴은 최소 10개 이상 찾아주세요.
다음과 같은 지시사항에 따라서 패턴을 인식해야합니다:
1. 하나의 문자메시지만 보고도 스팸 문자메시지인지 식별할 수 있는 패턴만 나열하세요.
2. 어떠한 특정 문자나 키워드에 집중하지 않아야 합니다. 해당 키워드의 예시를 제공하지 마세요.
3. 반복적인 키워드는 무시하세요.
4. 더 높은 수준의 추상적 표현으로만 스팸 문자메시지의 패턴을 찾아야합니다.
5. 단어의 키워드가 아닌 작성자의 글쓰기 스타일에 집중하세요.
6. 특히, ㉠ ㉡ ㉢ ㉮ ㉯ ㉰ Ⓐ Ⓑ Ⓒ 같은 원 안에 문자가 들어있는 특수기호가 등장했을 때는, 내부에 써있는 글자의 의미를 이해해주세요. 예를 들어, 집에 ㉮㉶는 집에 가자 입니다.
7. 링크가 있다고 해서, 반드시 스팸 메시지는 아닙니다. url이나 링크에서도 특정되는 패턴이 있다면, 찾아주세요.
좋은 예시:
1. 대량의 숫자 및 기호 사용: 문자 안에 다양한 숫자와 특수기호가 과도하게 삽입되어 있습니다. 예를 들어, 가격을 표시할 때 “,**,***원” 같은 형식으로 사용되며, 이는 숫자 사이의 콤마와 특수기호를 통해 시각적 강조를 의도한 것으로 보입니다. 또한 숫자를 강조하기 위해 ‘%’와 같은 기호를 반복적으로 사용하고 있습니다.
2. 비정상적인 띄어쓰기와 문장 구조: 메시지의 문장 구조가 비정상적이며, 띄어쓰기가 의도적으로 잘못 사용됩니다. 이는 메시지를 읽기 어렵게 만들어 스팸 필터를 피하려는 시도로 보입니다. 예를 들어, 단어 사이에 불필요한 공백을 삽입하거나, 문장을 비정상적으로 끊어 놓는 방식이 사용됩니다.
나쁜 예시:
1. 특수문자가 많이 포함되어 있습니다.
2. 링크가 첨부되어 있습니다.
3. "대박", "최고", "안전 보장"
모듈 2) 그 특성값을 받아서 데이터를 Danger, Warning, Safe를 판별하고, Danger, Warning 일떄 CoT를 출력하게 하는 모듈
방금 찾아낸 패턴을 참고하여 "문자메시지: " 에 입력된 메시지가 스팸 문자메시지인지 아닌지 구분해주세요.
출력 방식:
완전히 스팸 문자메시지 같다면, "Danger"을 출력해주시고,
스팸 문자메시지인지 아닌지 헷갈린다면, "Warning"을 출력해주시고,
스팸 문자메시지가 아니라면, "Safe"를 출력해주세요.
이외에도 당신이 이해하기에 스팸 문자메시지 같다면, 판단해서 출력해도 됩니다.
예시:
1. [국제발신] 나 돌아왔어, 좀 볼 수 있을까? Lline:i764j
2. 대학교 재학생 22세/166cm/47kg, 하룻밤 함께 할 수 있는 비용은 7만 원 사진은 ḺḻṈE 있어요:bv56n
출력 관련 사항:
출력은 "Danger", "Warning", "Safe"만 해주세요.
만약 "Danger"이거나 "Warning"이면, 왜 그렇게 추론했는지 이유를 CoT(Chain-of-Thought) 방식으로 써주세요.
만약 "Safe"일 경우, "Safe"로 추론한 이유는 알려주지 않으셔도 괜찮습니다.
출력 예시:
Danger
1. 비정상적인 URL 형식: 메시지에 포함된 URL이 비정상적인 형식을 가지고 있으며, 이는 사용자를 혼란스럽게 하거나, 스팸 필터를 피하려는 시도로 보일 수 있습니다.
2. 발신자 정보 부족: 발신자가 명확하지 않으며, 이는 스팸 메시지일 가능성을 높입니다.
3. 비정상적인 문장 구조: 메시지의 문장 구조가 비정상적이며, 이는 스팸 메시지에서 자주 사용되는 패턴입니다.
문자메시지:
[5] 우리의 attribute 를 어떻게 극적으로 보여 줄 수 있을까
기존 모델과 비교하기 위하여 다음과 같은 표를 가지고 왔지만 사실 좀 꼼꼼히 보면
다 0.99 인게 많아서 이렇게 보여주게 되면 얼마나 우리가 잘 classification 할지를 파악 할 수 없음으로
별도로 figure 를 뽑았다. (이거는.. 스스로 깨닳지는 못했고 한 박사님께 ppt 를 보여드렸는데, 이렇게 보여주면 뭘 보라는건지 모르니 뽑아서 보여주면서 설명이 필요하다고 말씀해 주시더라, 그리고 초안은 사실 accuracy 만 뽑았었다.)
혼동행렬 배운거 왜 안써먹냐고 좀 혼낫습니다. ㅎㅎ

이 표에서 Error Rate (오류율), Miss Rate (누락율), 그리고 False Positive Rate (오탐율)을 중요한 지표로 선택한 이유는, 이 세 가지가 모델의 스팸 탐지 성능을 종합적으로 평가하는 데 핵심적인 역할을 하기 때문이었습니다.
특히 False Positive Rate (오탐율)은 정상 메시지를 스팸으로 잘못 분류한 비율을 나타내는데, 정상 메시지가 스팸으로 분류되면 사용자 입장에서 불편을 초래하고, 정상적인 소통이 차단될 수 있기때문에 오탐율이 낮을수록 모델이 정상 메시지를 잘 보호하면서 스팸만 필터링하고 있다는 걸 내포합니다. 따라서 false Positive rate 까지 넣었습니다.
9. 회고
온전치 못한 정신을 가지고 약 4일 새벽시간 이용해서 12시-5시 이용해서 했으니 정신이 말짱할리가 없었다.
그리고 이건 우리의 주제명과 스팸 그림에서도 잘 드러난다..

놀랍게도 이...제목 그대로 초안 발표그대로 사용되었고, PPT 이미지도 그대로 사용되었다.


(1) 시간적 버퍼를 만들어놓고 도전하자.
이번에는 부득이하게 주제가 엎어지면서 어쩔수 없었지만 요즘 느끼는건데 이것저것 해보고싶은게 많아서 도전하고는 있지만 저질러놓고 해결하는 형식의 프로젝트 진행은 몸을 축나게 만든다...
(2) 시간이 많았으면 Classic 한 스팸문자 거르는 문제에서 조금 벗어날수 있지 않았을까.... 아쉽다.
하지만 4일 새벽 시간대를 이용해서 뚝딱 만들어낸것 치곤 우수상 너무 뿌듯했다.

그러나, 다음에는 모델 부분에서 고민하고 공부 할 수 있는 플젝해보기 (공부하고 많이 고민하고 졸업해야한다)