2024. 8. 21. 18:05ㆍ카테고리 없음
https://www.youtube.com/watch?v=1scMJH93v0M&t=16s
https://github.com/teddylee777/langchain-kr/blob/main/12-RAG/01-RAG-Basic-Webloader.ipynb
langchain-kr/12-RAG/01-RAG-Basic-Webloader.ipynb at main · teddylee777/langchain-kr
LangChain 공식 Document, Cookbook, 그 밖의 실용 예제를 바탕으로 작성한 한국어 튜토리얼입니다. 본 튜토리얼을 통해 LangChain을 더 쉽고 효과적으로 사용하는 방법을 배울 수 있습니다. - teddylee777/langch
github.com
~기반으로 알려줘 = RAG를 이용하여 만들어야함!


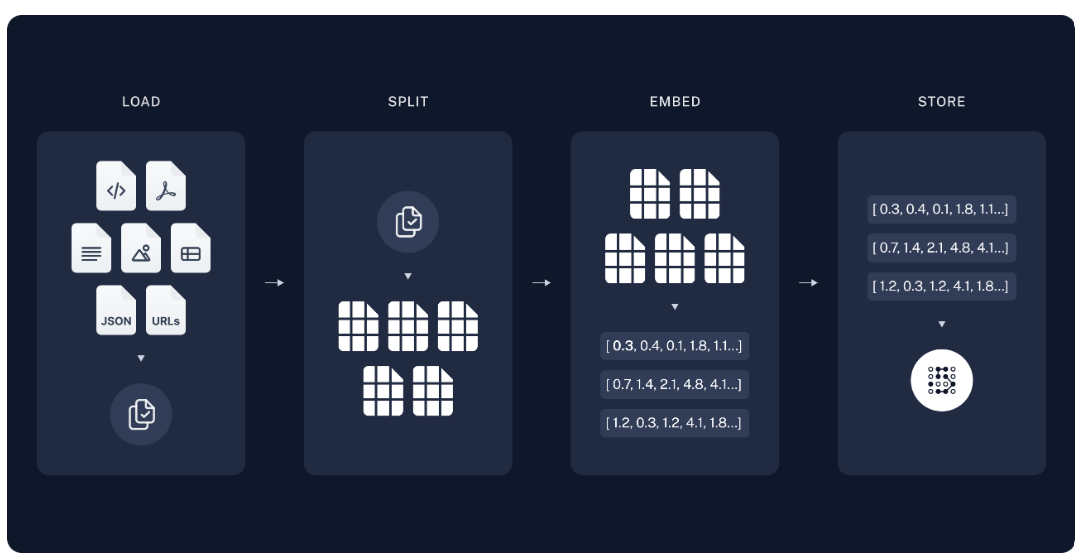
사전 작업 단계에서는 데이터 소스를 Vector DB (저장소) 에 문서를 로드-분할-임베딩-저장 하는 4단계를 진행합니다.
- 1단계 문서로드(Document Load): 문서 내용을 불러옵니다.
- 2단계 분할(Text Split): 문서를 특정 기준(Chunk) 으로 분할합니다. - 분할을 어떻게 하는지가 퀄리티가 달라진다
- 3단계 임베딩(Embedding): 분할된(Chunk) 를 임베딩하여 저장합니다.
- 4단계 벡터DB 저장: 임베딩된 Chunk 를 DB에 저장합니다.
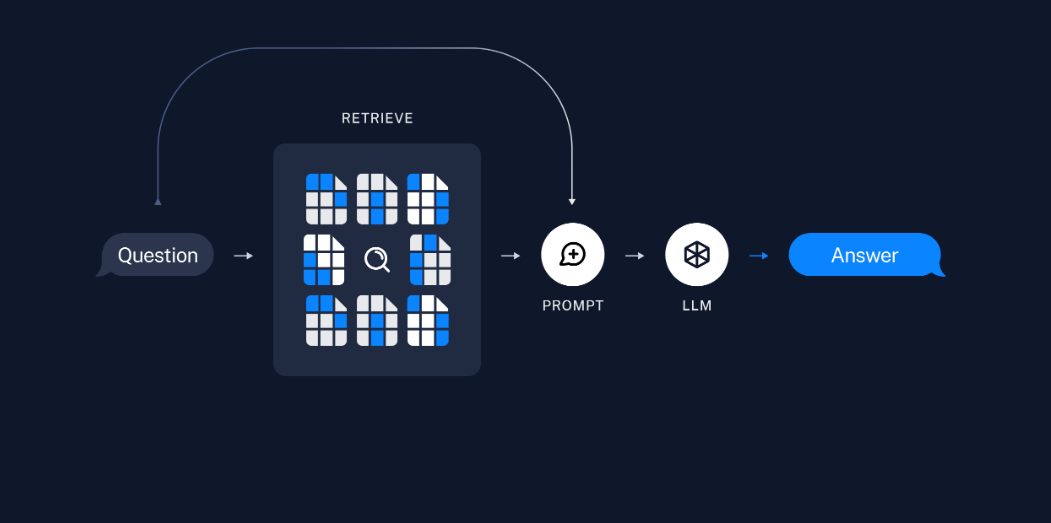
- 5단계 검색기(Retriever): 쿼리(Query) 를 바탕으로 DB에서 검색하여 결과를 가져오기 위하여 리트리버를 정의합니다. 리트리버는 검색 알고리즘이며(Dense, Sparse) 리트리버로 나뉘게 됩니다.
*Dense: 유사도 기반 검색, Sparse: 키워드 기반 검색 - 6단계 프롬프트: RAG 를 수행하기 위한 프롬프트를 생성합니다. 프롬프트의 context 에는 문서에서 검색된 내용이 입력됩니다. 프롬프트 엔지니어링을 통하여 답변의 형식을 지정할 수 있습니다.
- 7단계 LLM: 모델을 정의합니다.(GPT-3.5, GPT-4, Claude, etc..)
- 8단계 Chain: 프롬프트 - LLM - 출력 에 이르는 체인을 생성합니다.
100장 짜리일때 1개의 주제가 1장이라고 한다면, 100개의 주제됨
만약 10장으로 쪼개면 10개의 주제가 혼합 될 수 밖에 없음 - 그니까 잘 쪼개야함
그래서 데이터의 품질은 Split docs 로 쪼개야함
오 langmith hub 라는 좋은게 있군 - langsmith 공부가 좀더 필요할것같음
https://smith.langchain.com/hub

RAPTOR! 논문 리뷰
https://www.youtube.com/watch?v=gcdkISrpMCA
긴문서가 들어왔을떄 효율적으로 RAG를 어떻게 잘 구현하는지를 보여준 논문임
RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
(트리로 구성된 검색을 위한 재귀적 추상 처리)
**논문: https://arxiv.org/pdf/2401.18059v1.pdf**
- 대부분의 기존 방법은 검색 코퍼스에서 짧은 연속 청크만 검색하여 전체 문서 컨텍스트에 대한 전체적인 이해를 제한
- 기존의 검색 증강 접근 방식에도 결함이 있습니다. 우리가 해결하는 것은 대부분의 기존 방법이 몇 개의 짧고 연속적인 텍스트 청크만 검색하여 대규모 담론 구조를 표현하고 활용하는 능력이 제한된다는 것
- 이는 NarrativeQA 데이터셋(Koˇcisk`y et al., 2018)에서와 같이 텍스트의 여러 부분에서 지식을 통합해야 하는 주제별 질문에 특히 관련이 있습니다. 신데렐라의 동화와 "신데렐라는 어떻게 행복한 결말을 맞이했는가?"라는 질문을 생각해 보세요. 상위 k개 검색된 짧은 연속 텍스트에는 질문에 답변할 만큼 충분한 맥락이 포함되지 않습니다. > 단순히 몇개를 가져오는것 만으로는 제한이 될 수 있다.
RAPTOR
- 텍스트 청크를 재귀적으로 임베딩, 클러스터링, 요약하는 새로운 접근 방식을 소개하여 하단에서 상단으로 요약 수준이 다른 트리를 구성
- 추론에 RAPTOR 모델은 이 트리에서 검색하여 다양한 추상화 수준에서 긴 문서의 정보를 통합합니다.
- 통제된 실험에 따르면 재귀적 요약을 통한 검색은 여러 작업에서 기존의 검색 증강 LM보다 상당한 개선을 제공
- RAPTOR 검색을 GPT-4 사용과 결합하면 QuALITY 벤치마크에서 절대 정확도를 20%까지 향상시킬 수 있습니다.
메인 기여는 다양한 규모에서 컨텍스트의 검색 증강을 허용하고, 긴 문서 컬렉션에 대한 실험에서 그 효과를 보여주기 위해 텍스트 요약을 사용한다는 아이디어

핵심이 TREE 구조를 만든는것! 비슷한 문장들끼리는 묶어주고 요약문을 만들어주는 것임!
결국 6,7,8은 요약본이 되는 것임! (점점 추상화를 한다!)
Why Retrieval?
- 하드웨어와 알고리즘의 최근 발전으로 모델이 처리할 수 있는 컨텍스트 길이가 확장되어 검색 시스템의 필요성에 대한 의문이 제기되었습니다(Dai et al., 2019; Dao et al., 2022; Liu et al., 2023).
- 그러나 Liu et al. (2023)과 Sun et al. (2021)이 지적한 바와 같이 모델은 Long Context 를 충분히 활용하지 못하는 경향이 있으며, 특히 관련 정보가 긴 컨텍스트에 포함되어 있는 경우 컨텍스트 길이가 증가함에 따라 성능이 저하됩니다.
- 게다가 실제로 긴 컨텍스트를 사용하는 것은 비용이 많이 들고 느립니다. 이는 지식 집약적 과제에 가장 관련성 있는 정보를 선택하는 것이 여전히 중요함을 시사합니다.

질문 비용이 이렇게 길게 되면 아무도 사용하지 않을 것임! 디테일한 내용을 가지고 오지 못하는 문제점이 있음
이걸 해결하기위해
렉터라는 개념을 들고옴
Recursive summarization as Context
- 재귀적 요약을 컨텍스트 요약 기법으로 사용하면 문서의 요약된 뷰를 제공하여 콘텐츠에 더 집중적으로 참여할 수 있습니다(Angelidis & Lapata, 2018).
- Gao et al.(2023)의 요약/스니펫 모델은 구절의 요약과 스니펫을 사용하여 대부분의 데이터 세트에서 정확성을 향상시키지만 때로는 손실이 많은 압축 수단이 될 수 있습니다.
- Wu et al.(2021)의 재귀적 추상 요약 모델(재귀적으로 추상화된 요약을 생성: map-reduce)은 작업 분해(task decomposition) 를 사용하여 더 작은 텍스트 청크를 요약하고 나중에 통합하여 더 큰 섹션의 요약을 만듭니다. 이 방법은 더 광범위한 테마를 포착하는 데 효과적이지만 세부적인 내용을 놓칠 수 있습니다.
- LlamaIndex(Liu, 2022)는 유사한 방식으로 인접한 텍스트 청크를 요약하지만 중간 노드를 유지하여 다양한 수준의 세부 정보를 저장하고 세부적인 내용을 유지함으로써 이 문제를 완화합니다. 그러나 두 방법 모두 인접한 노드를 그룹화하거나 요약하기 위해 인접성에 의존하기 때문에 텍스트 내에서 RAPTOR로 찾아서 그룹화할 수 있는 먼 상호 의존성을 간과할 수 있습니다. > 문제점이 있음!
알고리즘
문서 클러스터링
- RAPTOR 트리 구축은 검색 코퍼스를 전통적인 검색 증강 기법과 유사하게 길이 100의 짧고 연속적인 텍스트로 분할하는 것으로 시작됩니다. 문장이 100토큰 제한을 초과하면 문장을 중간에 자르는 대신 전체 문장을 다음 청크로 이동합니다. 이렇게 하면 각 청크 내에서 텍스트의 맥락적, 의미적 일관성이 유지됩니다.
- 유사한 텍스트 청크를 그룹화하기 위해 클러스터링 알고리즘을 사용합니다. 클러스터링이 완료되면 언어 모델을 사용하여 그룹화된 텍스트를 요약합니다. 이렇게 요약된 텍스트는 다시 임베딩되고, 임베딩, 클러스터링, 요약의 사이클은 더 이상 클러스터링이 불가능해질 때까지 계속되어 원본 문서의 구조화된 다층 트리 표현이 됩니다.
- RAPTOR의 중요한 측면은 계산 효율성입니다. 이 시스템은 빌드 시간과 토큰 지출 측면에서 선형적으로 확장되므로 대규모의 복잡한 코퍼스를 처리하는 데 적합합니다.
- 이 트리 내에서 쿼리하기 위해 트리 순회와 축소된 트리라는 두 가지 고유한 전략을 도입합니다. 트리 순회 방법은 트리를 계층별로 순회하면서 각 수준에서 가장 관련성 있는 노드를 가지치고 선택합니다.
- 축소된 트리 방법은 모든 계층에서 노드를 집합적으로 평가하여 가장 관련성 있는 노드를 찾습니다.
- 클러스터링 알고리즘 클러스터링은 RAPTOR 트리를 구축하고 텍스트 세그먼트를 응집력 있는 그룹으로 구성하는 데 핵심적인 역할을 합니다. 이 단계에서는 관련 콘텐츠를 그룹화하여 후속 검색 프로세스에 도움이 됩니다.
- 클러스터링 접근 방식의 고유한 측면 중 하나는 소프트 클러스터링을 사용하는 것으로, 노드는 고정된 수의 클러스터가 필요하지 않고 여러 클러스터에 속할 수 있습니다. 이러한 유연성은 개별 텍스트 세그먼트에 종종 다양한 주제와 관련된 정보가 포함되어 여러 요약에 포함되어야 하기 때문에 필수적입니다.
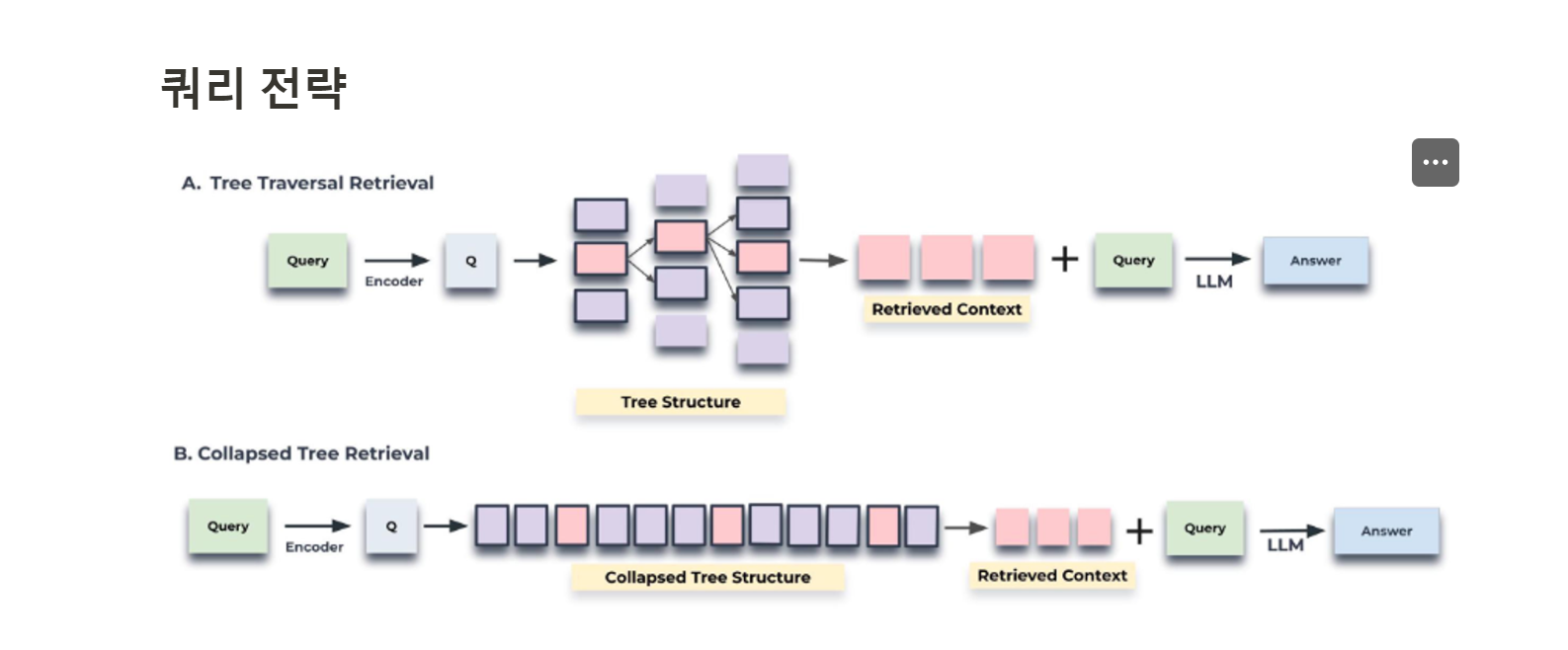
원래 잘게쪼개진 청크로부터 클러스터링을 하고 요약본을 만들고를 재귀적으로 만든건데..
이것을 단순하게 B는 평탄화를 해서 펼처주는 건데 > 우리 사용자가 질문이 드어오면 노드들의 유사성을 검색해서...
- 쿼리는 Root 노드와의 코사인 유사도 계산으로 시작
- 가장 관련성 높은 K 개의 노드(그림에서는 k=1 예시입니다)를 initial layer 로부터 노드를 선택하고 첫 번째 Set1 을 생성
- Set1 의 자식 노드에서 쿼리 임베딩과 자식 노드간 코사인 유사도를 계산
- 이 중 유사도 높은 자식 노드로 Set2 를 생성
- Set1 ~ Set n 단일 계층으로 축소(평탄화)하고 쿼리 벡터와의 코사인 유사도를 기준으로 임계값 토큰 수에 도달할 때까지 노드를 검색합니다. (코사인 유사도 검색이 수행되는 노드는 두 그림에서 모두 강조 표시)
축소된 트리 접근 방식은 그림에 나와 있듯이 트리의 모든 노드를 동시에 고려하여 관련 정보를 검색하는 더 간단한 방법을 제공합니다.
- 먼저 전체 RAPTOR 트리를 단일 레이어로 축소합니다. Collapsed Tree Structure로 표시된 이 새로운 노드 집합에는 원래 트리의 모든 레이어의 노드가 포함됩니다.
- 다음으로 축소된 집합 C에 있는 모든 노드의 임베딩과 쿼리 임베딩 간의 코사인 유사도를 계산합니다.
- 마지막으로, 쿼리와 가장 높은 코사인 유사도 점수를 가진 상위 k 노드를 선택합니다. 모델의 입력 제한을 초과하지 않도록 하면서 사전 정의된 최대 토큰 수에 도달할 때까지 결과 세트에 노드를 계속 추가합니다.
적정 최대 토큰수 실험 (2000 토큰이 optimal 했다고 함)
- 이는 유사도 상위 20개의 노드 정보를 반영한 것과 같음 (1개 노드당 100 토큰이니깐..)


가중치 파일..? 나이 추정에서도 나눠서 저장될 것임
https://writenkeep.tistory.com/6
트리 구축
트리 구축에서의 클러스터링 접근 방식에는 몇 가지 흥미로운 아이디어가 포함되어 있습니다.
GMM (가우시안 혼합 모델)
- 다양한 클러스터에 걸쳐 데이터 포인트의 분포를 모델링합니다.
- 모델의 베이지안 정보 기준(BIC)을 평가하여 최적의 클러스터 수를 결정합니다.
UMAP (Uniform Manifold Approximation and Projection)
- 클러스터링을 지원합니다.
- 고차원 데이터의 차원을 축소합니다.
- UMAP은 데이터 포인트의 유사성에 기반하여 자연스러운 그룹화를 강조하는 데 도움을 줍니다.
지역 및 전역 클러스터링
- 다양한 규모에서 데이터를 분석하는 데 사용됩니다.
- 데이터 내의 세밀한 패턴과 더 넓은 패턴 모두를 효과적으로 포착합니다.
임계값 설정
- GMM의 맥락에서 클러스터 멤버십을 결정하기 위해 적용됩니다.
- 확률 분포를 기반으로 합니다(데이터 포인트를 ≥ 1 클러스터에 할당).
아 논문 리뷰는 이렇게 하는 거구나... 를 느꼈음
영상을 보고 논문을 읽으면 이해가 되는데 논문부터 시작... ^-^... 쉽지 않다.
우선 그래도 RAPTOR 는 RAG의 한계를 극복하기 위해 개발된 기술로, 긴 텍스트나 복잡한 문서 구조를 더 잘 처리할 수 있도록 도와주는 것!
RAPTOR
| 1. 단순 임베딩 기반 접근 | 2. RAPTOR 기반 접근 |
단순 임베딩 기반 접근에서는 일반적으로 다음과 같은 단계를 거칩니다:
|
RAPTOR는 이 과정에 추가적인 단계와 트리 구조를 도입합니다:
|
| from sentence_transformers import SentenceTransformer from sklearn.metrics.pairwise import cosine_similarity # 사전 훈련된 임베딩 모델 로드 model = SentenceTransformer('all-MiniLM-L6-v2') # 문서와 쿼리 docs = ["Document 1 content...", "Document 2 content...", "Document 3 content..."] query = "What is the main theme of Document 1?" # 문서와 쿼리를 임베딩 doc_embeddings = model.encode(docs) query_embedding = model.encode(query) # 쿼리와 문서 간의 유사도 계산 similarities = cosine_similarity([query_embedding], doc_embeddings) # 유사도에 따라 상위 문서를 선택 top_k_indices = similarities.argsort()[0][-k:] top_docs = [docs[i] for i in top_k_indices] # 상위 문서를 기반으로 텍스트 생성 (예시: OpenAI의 GPT 사용) generated_text = gpt_model.generate(top_docs) |
from sentence_transformers import SentenceTransformer from sklearn.cluster import AgglomerativeClustering # 사전 훈련된 임베딩 모델 로드 model = SentenceTransformer('all-MiniLM-L6-v2') # 문서를 일정 크기의 청크로 나눕니다. def split_into_chunks(document, chunk_size=100): return [document[i:i+chunk_size] for i in range(0, len(document), chunk_size)] # 문서 청크 생성 chunks = [] for doc in docs: chunks.extend(split_into_chunks(doc)) # 청크 임베딩 chunk_embeddings = model.encode(chunks) # 청크 클러스터링 clustering = AgglomerativeClustering(n_clusters=None, distance_threshold=1.0) cluster_labels = clustering.fit_predict(chunk_embeddings) # 클러스터별 텍스트 요약 생성 (예: GPT-3.5 사용) def generate_summary(texts): combined_text = " ".join(texts) summary = gpt_model.summarize(combined_text) return summary # 클러스터별 요약 생성 및 임베딩 cluster_summaries = [] for cluster_id in set(cluster_labels): cluster_texts = [chunks[i] for i in range(len(chunks)) if cluster_labels[i] == cluster_id] summary = generate_summary(cluster_texts) cluster_summaries.append(summary) summary_embeddings = model.encode(cluster_summaries) class Node: def __init__(self, embedding, summary, children=None): self.embedding = embedding self.summary = summary self.children = children if children is not None else [] # 루트 노드를 생성하고 트리 구조를 구축합니다. root_node = Node(embedding=None, summary="Root Summary", children=[]) for i, embedding in enumerate(summary_embeddings): root_node.children.append(Node(embedding, cluster_summaries[i])) # 트리 탐색을 위한 재귀 함수 def traverse_tree(node, query_embedding, top_k=5): if not node.children: # 리프 노드인 경우 return [(node, cosine_similarity([query_embedding], [node.embedding])[0][0])] # 자식 노드들에 대해 유사도 계산 similarities = [(child, cosine_similarity([query_embedding], [child.embedding])[0][0]) for child in node.children] # 유사도에 따라 상위 노드 선택 similarities = sorted(similarities, key=lambda x: x[1], reverse=True) # 재귀적으로 자식 노드 탐색 results = [] for child, sim in similarities[:top_k]: results.extend(traverse_tree(child, query_embedding, top_k)) return results # 쿼리를 트리에 대해 탐색 relevant_nodes = traverse_tree(root_node, query_embedding) retrieved_texts = [node.summary for node, _ in relevant_nodes] # 검색된 텍스트 요약을 기반으로 최종 텍스트 생성 final_generated_text = gpt_model.generate(retrieved_texts) |